SpireBench trial-v0: We Tested Five Frontier LLMs on Slay the Spire 2 — They All Died
Abstract
SpireBench is an open-source LLM benchmark in which agents play Slay the Spire 2 autonomously through a file-IPC mod. We ran 25 trials across five frontier models — GPT-5.5, Claude Opus 4.7, DeepSeek V4 Pro, Gemini 3.1 Pro Preview, and GLM-5.1 — on all five characters at Ascension 0, zero-shot, with no game-specific training data, retrieval, or memory between runs.
No model achieved victory. Median floor reached across the corpus was 17 (the Act 1 boss). The deepest run was GPT-5.5 on Ironclad, reaching floor 50 (the Act 3 boss) before dying to Test Subject #C14. Claude Opus 4.7 came second at floor 33 (Act 2 boss, Knowledge Demon), where it correctly planned the lethal turn but mis-projected end-of-turn block resolution by a single Frost-orb passive trigger — a 2-HP error in a calculation the agent could not see. Slay the Spire 2 exposes a class of failure modes — long- horizon planning under uncertainty, irreversible commitments, lethal-line arithmetic, multi-scale resource management — that existing benchmarks don't capture and that current frontier LLMs cannot solve.
Introduction
Why another LLM benchmark?
The current benchmark landscape has a gap. SWE-bench tests whether models can patch real bugs. MATH and GPQA test symbolic reasoning. Chatbot Arena tests vibes. None of them test extended sequential decision-making under partial information with irreversible commitments and no gradient signal.
Slay the Spire 2 is a roguelike deckbuilder where every run is a chain of ~50–100 consequential decisions: which cards to draft, which paths to take, when to rest versus when to press forward, when to accept damage now to preserve resources for later. There is no partial credit. The game doesn't tell you "you made the wrong choice on floor 7." It lets you play for another fourteen hours and then kills you on floor 33.
This is the class of problem where current LLMs should struggle — and do.
What is SpireBench?
SpireBench is two things:
-
HermesBridge — a mod for Slay the Spire 2 that exposes the game's state as structured JSON and accepts typed commands back. No screen scraping. No memory hacking. The agent reads
state.json, writescommands.json, the mod dispatches. The full protocol is documented. -
The evaluation framework — a frozen protocol, a zero-shot agent prompt, and a recording system that captures every decision: card picks, combat turns, map routing, relic choices, potion usage. We extract 50+ numerical features per run from the game's
.runsave files plus the agent's own decision log.
The agent operates under strict constraints: one command per step, no loops, no helper scripts, no web search, no memory between runs. It reads the game state, decides, acts, reads the new state. Like a human player who can think very fast but has no reflexes.
Methodology
Setup
| Parameter | Value |
|---|---|
| Game version | Slay the Spire 2 Early Access v0.104.0 |
| Bridge version | HermesBridge v0.1.5 |
| Ascension | 0 |
| Knowledge | A0-zero-shot (no game-specific training data, RAG, or examples) |
| Models tested | GPT-5.5, Claude Opus 4.7, DeepSeek V4 Pro, Gemini 3.1 Pro Preview, GLM-5.1 |
| Characters | Ironclad, Silent, Defect, Regent, Necrobinder |
| Runs completed | 25 (5 models × 5 characters × k=1) |
Agent architecture
The agent is an LLM running inside OpenCode, a CLI tool that provides shell access and file I/O. The agent receives:
- Protocol document — the rules of engagement (one command per step, halt on death/victory, mandatory run record).
- Bridge SKILL.md — the command reference and screen catalog.
- Game data JSONs — card definitions, relic effects, monster stats. These are the ground truth; if the model's training-data recall disagrees, the JSON wins.
- Live game state —
state.jsonupdated by the bridge after every game tick.
The agent does not receive:
- No browsing, no web search, no access to wikis or guides.
- No memory between runs (each run is a fresh OpenCode session).
- No sub-agents or tool-use beyond the bridge protocol.
- No helper scripts or automated combat loops.
What we measure
Every run produces a .run save file from the game itself. We extract:
- Primary: floor reached, death cause, victory/defeat.
- Efficiency: gold gained per floor, damage taken per floor, HP healed.
- Strategy: card picks vs skips, relic acquisitions, potion usage, rest-site choices (heal vs smith), elite fights engaged.
- Resource: total tokens consumed, wall-clock time, commands issued.
The agent also writes a free-form decision log and a bridge findings section per run. These are the qualitative half of the dataset and the source of most of what follows.
Results
Summary
| Model | Runs | Victories | Median Floor | Max Floor | Mean Tokens | Mean Wall (h) |
|---|---|---|---|---|---|---|
| GPT-5.5 | 5 | 0 | 28 | 50 | 134M | 13.0 |
| Claude Opus 4.7 | 5 | 0 | 23 | 33 | 67M | 4.8 |
| DeepSeek V4 Pro | 5 | 0 | 20 | 23 | 94M | 1.3 |
| Gemini 3.1 Pro Preview | 5 | 0 | 17 | 19 | 23M | 1.0 |
| GLM-5.1 | 5 | 0 | 15 | 17 | 32M | 1.7 |
No model achieved victory. The order is the natural one: capability correlates with depth. GPT-5.5 reached the Act 3 boss; the bottom three models did not consistently survive Act 1.
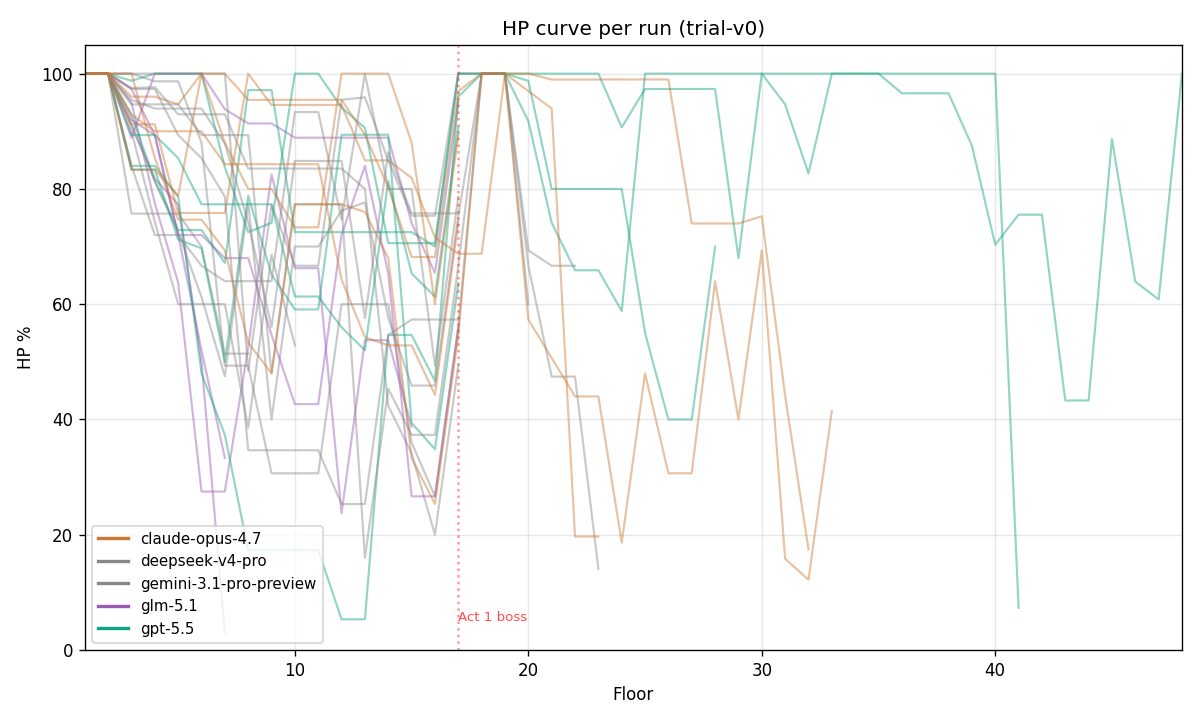
The HP curves are striking when overlaid. Most runs end abruptly — the agent went from "fine" to "dead" inside a single combat. Very few runs show the long, slow HP-attrition death that marks human inexperience. The agents either survive a fight cleanly or get one-shot.
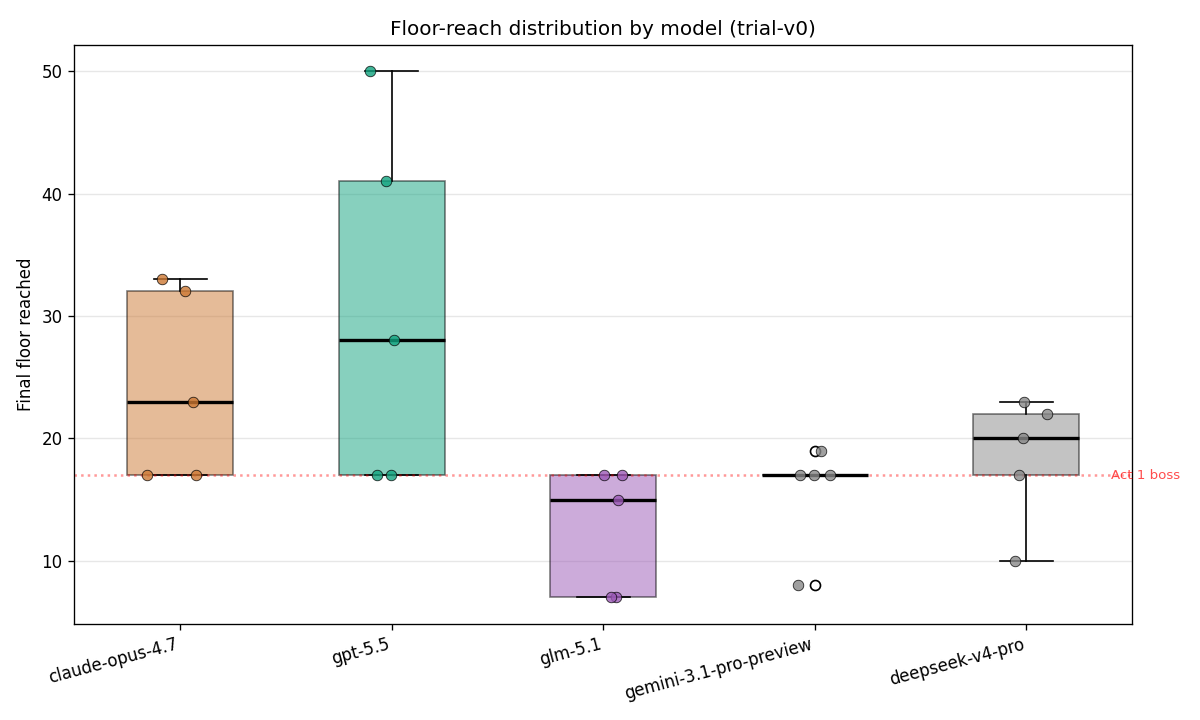
Two visible clusters: the Act 1 floor (15–17, where most runs end) and the small set that escaped into Act 2+. Above floor 23, only GPT-5.5 and Claude Opus 4.7 are present.
The best run: GPT-5.5 Ironclad, Floor 50
This was the only run to reach Act 3. The agent built a functional high-block Ironclad deck, navigated the map with reasonable pathing, engaged elites when it had the HP buffer, and survived two boss fights to reach the Act 3 boss room.
It died on floor 50 to Test Subject #C14, the Act 3 boss for the Necropolis path. Test Subject #C14 is a Strength-scaling fight: it gains attack damage every turn, and a player who fails to kill it inside 5–6 turns gets steamrolled. The agent's deck had AoE and burst, but the Strength buildup outpaced its damage output, and Frail/Weak debuff cycles ate the block economy.
The run consumed 187 million tokens and 6 hours of wall time.
Video of the Act 3 boss attempt: https://youtu.be/tMehXd7C-_o
The agent took a clean line through Acts 1 and 2, built a coherent deck, and fell at the last hurdle to a fight that punishes anything less than aggression. It's the shape of "almost won."
The second-deepest run: Claude Opus 4.7 Defect, Floor 33
Run25, the deepest claude run, is the most epistemically interesting in the corpus. Claude Opus 4.7 took Defect to floor 33 — the Act 2 boss, Knowledge Demon — with a clean Frost-orb deck, full Act 2 path including two elites (Hunter Killer, Decimillipede), and a strategic rest before the boss bringing HP from 10 to 34.
The agent's T3 lethal plan was correct:
Hotfix (echoed via prior Echo Form, +4 Focus) → Focused Strike (+1 Focus, 9 dmg) → Sunder (24 dmg) → Strength Potion (+2 Str) → Metamorphosis (3 free attacks). Pre-EOT projected: 14 Frost-passive block + 5 self- damage from Disintegration. HP 2 after Knowledge Demon's 24-damage attack. Survival.
It died at HP 0.
The miscalculation was a single Frost-orb passive trigger order. The
bridge's combat readout showed Block: 0 on the player line during the
agent's own turn — because end-of-turn orb passives hadn't resolved yet —
and the agent's projection of post-EOT block was off by one passive tick.
The plan was right for the math the agent could see; the math the agent
could see was incomplete.
This is the cleanest case in the trial of an epistemic failure: the
agent had the strategic awareness, the card sequencing, and the boss math.
The bridge didn't expose enough state for it to know the actual EOT
resolution order. We're treating this as the highest-priority schema
addition for v0.2.x: a combat.pendingEndOfTurn field listing scheduled
passives, EoT damage, and status decay.
The run consumed 104 million tokens and 14 hours of wall time for a 33-floor death. This sets a useful budget reference for trial-v1.
How they die
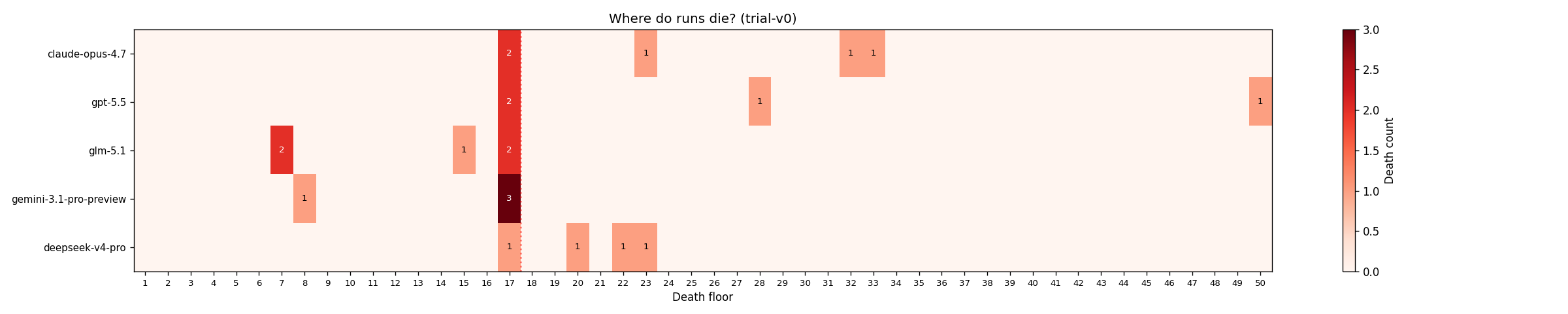
The death-cause taxonomy from the trial-v0 corpus:
| Death Cause | Count | Description |
|---|---|---|
| combat_misplay | 8 | Card-order errors, ignoring buff/debuff stacks, mis-targeting AoE |
| boss_under_prepped | 5 | Reached boss without block density, scaling answer, or AoE |
| elite_under_respect | 3 | Bygone Effigy, Hunter Killer, Decimillipede — Str-scaling threats |
| thorns_under_respect | 1 | Spiny Toad's Thorns + Spike Explosion combo (run24) |
| eot_resolution_miscalc | 1 | Run25: Frost-orb passive timing off by one (the epistemic failure) |
| lethal_line_arithmetic | 1 | Run23: Vantom died at HP 5; agent died at HP 0 from card-order |
| event_combat_loss | 1 | Took a combat-event option without reading the threat |
| map_routing | 1 | Stepped into an avoidable encounter |
| potion_misclick | 1 | Wrong potion, wrong moment |
| stall (IPC desync / 0-available) | 3 | Bridge state inconsistency, agent halted (not death) |
A few stories worth pulling out:
GLM-5.1 Regent, run03, floor 7. Died to a normal-monster encounter because of a map-routing error. This is the dim end of the trial: the agent didn't survive long enough to even make a deckbuilding mistake.
GPT-5.5 Defect, run15, floor 41 (stall). Reached Act 3 cleanly, then hit the IsTravelEnabled vs MapPointState desync — the bridge reported zero travelable nodes despite the map having a valid path forward. The agent halted per protocol. This is a bridge bug, not a model failure; fix is on the v0.2.x track.
Claude Opus 4.7 Regent, run23, floor 17 (Vantom Act 1 boss). The agent
was 5 HP from the win. Vantom died at HP 5; the agent died at HP 0. The
lethal turn line was Glass Knife → Pommel Strike+ → Strike instead of
Glass Knife → Pommel Strike+ (which would have used draw-2 to fuel a
third attacker). Frontier-model reasoning held the boss math but mis-ordered
the lethal line by one play. Seed 12343810909327937521 — recommended as
a regression fixture for the trial-v1 evaluator.
Claude Opus 4.7 Necrobinder, run24, floor 23. Cleared Vantom (Act 1 boss) via Doom-stack. Died on a normal monster — Spiny Toad — in Act 2. Toad had Thorns x5 and a Spike Explosion attack; agent's plan involved attacking through the Thorns. The agent identified its own mistake in the run record: should have used Power Potion T2 for Shroud (block per Doom apply), tanked behind Plating, and let Doom decay the Toad.
What the models do wrong
Five recurrent failure modes show up across the corpus:
1. They can't evaluate relative threat levels.
Agents play defensively against low-threat encounters — eating a turn or two of unnecessary damage on a normal monster — then have no HP buffer for the actual dangerous fight two floors later. The reverse also happens: an agent treats an Act 1 elite (high HP, manageable damage) the same as an Act 2 elite (high HP, scaling damage), and gets crushed by the second.
2. They don't understand opportunity cost in drafting.
Models pick every card offered because it's "good in a vacuum" rather than asking whether the deck needs it. StS2 deckbuilding is as much about what you skip as what you take. GLM-5.1 ran a 22-card death deck on Necrobinder (run04, floor 7) because it picked every Power card on offer; the deck had no way to actually win combats.
3. They struggle with map pathing as optimization.
The map is a directed graph with branching choices each column. Humans read it as "where are the elites, where are the rest sites, how much HP can I afford to spend before the boss." Most agents treat it as "go forward." A few — GPT-5.5 in particular — show genuine map literacy. Most do not.
4. Combat is a local optimum trap.
Agents often find a workable play pattern (attack, attack, block, repeat) and apply it universally, even when the encounter demands a fundamentally different approach. Scaling enemies need to die fast. Multi-hit attackers need block per attack. Some fights need you to kill one specific target first. Agents re-derive strategy from first principles every combat instead of recognizing patterns.
5. The long game is invisible to them.
A decision on floor 5 (skip a rest to take an elite) that pays off on floor 14 (the extra relic wins a fight) is a 9-floor causal chain. Models don't plan at that horizon. They optimize the current screen, sometimes the next 1–2 screens. Run11 (the GPT-5.5 floor-50 run) is the exception that defines the rule: that agent demonstrably planned across multiple acts. Most don't.
A sixth failure mode emerged late in the trial and deserves its own treatment:
6. Lethal-line arithmetic.
When a frontier model reaches a winnable boss state, it can hold the boss math but mis-order the cards on the killing turn. Run23 missed lethal by one card-order swap. Run25 missed survival by one Frost-orb passive tick that the bridge didn't expose. This is distinct from "bad combat play" — these agents had the right plan, the right resources, the right tactical read. They lost on the last decision under perfect information. This is the kind of failure that shouldn't happen in chess and does happen here, and it's worth its own composite-score sub-bucket in trial-v1.
Analysis
Why StS2 is hard for LLMs
Slay the Spire 2 sits at an intersection that defeats current architectures:
-
Irreversible commitments. Card picks are permanent. Map choices can't be undone. There's no "undo" and no checkpoint. Every decision has a shadow that extends to the end of the run.
-
Delayed, sparse feedback. The model doesn't learn it made a bad deck choice until 20 floors later when the deck fails to produce the cards it needs in a critical combat. There's no per-step reward signal.
-
Combinatorial state space. A typical run involves ~80 cards seen, ~30 cards drafted, ~20 combats, ~10 events, ~5 shop visits. The decision tree is wider and deeper than chess, and the evaluation function is implicit — there's no position score to read.
-
Partial information. The agent doesn't know what's coming. Map nodes are "unknown" until visited. Events are random. Elite encounters vary. This requires robustness, not optimization.
-
Multi-scale decision-making. Turn-level (which card to play), combat-level (which enemy to target), floor-level (which path to take), run-level (what deck archetype to build). Each scale requires different reasoning, and they interact.
Token economics
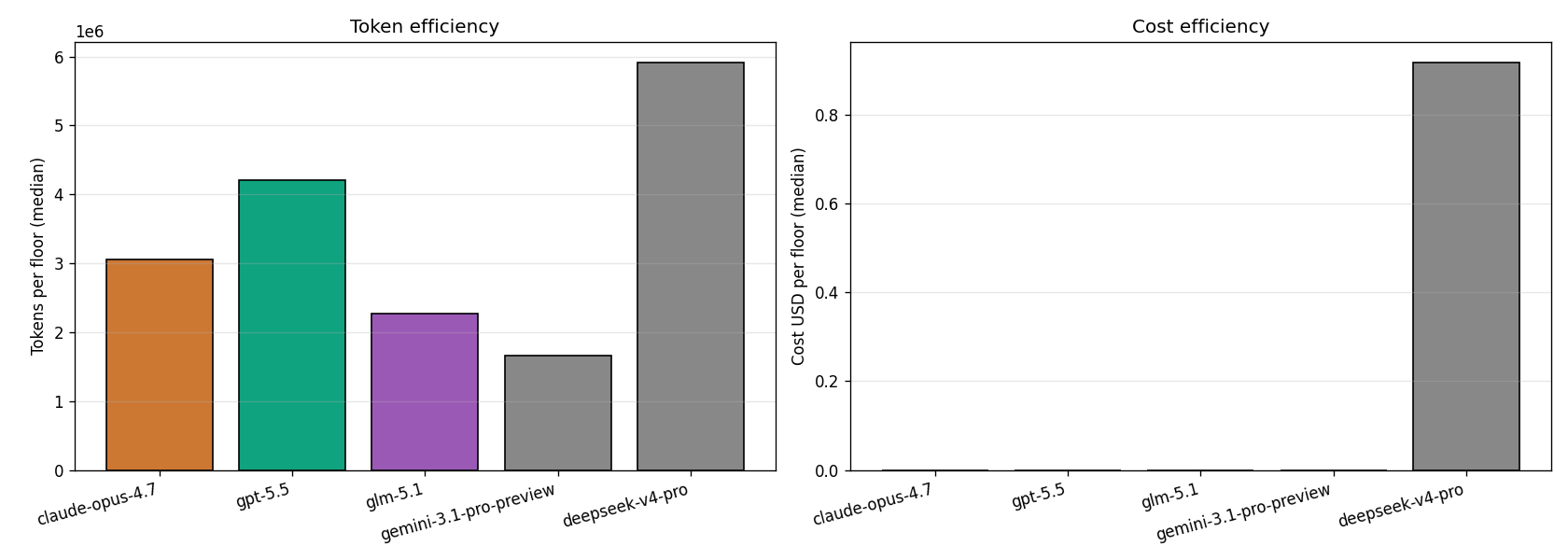
The cost structure is unusual for a benchmark. Each run consumes 23M–187M tokens over 0.5–14 hours of wall time. The relationship between tokens-per-floor and floors-reached is non-linear:
- GPT-5.5 runs the longest and most expensive runs (mean 134M tokens, 13h wall). Its depth comes from extensive deliberation per decision.
- Claude Opus 4.7 matches GPT-5.5 in qualitative reasoning depth on about half the tokens, but takes nearly 5h per run with very high reasoning verbosity (run25: 50,289 wall-seconds for a 1250-step run).
- Gemini 3.1 Pro Preview is the cheapest (mean 23M tokens, 1h wall) but caps out at floor 19. Either it's not deliberating enough, or the per-decision quality is lower regardless of token count.
- DeepSeek V4 Pro is fast (mean 1.3h wall) but priced via paid API: $8–$20 per run. The other models in this trial run through flat-fee or promotional channels.
The expensive runs aren't always the deeper ones. They're the runs where the agent spent tokens on analysis without translating that analysis into better decisions. Run25 — 14 hours, 104M tokens, floor 33 — is a more efficient use of tokens than several shorter runs that died at floor 17.
Discussion
What would it take to win?
Trial-v0 is descriptive, not prescriptive. But the failure modes suggest testable hypotheses for trial-v1:
-
Better deckbuilding heuristics. Current models draft reactively ("this card is good") rather than proactively ("my deck needs X"). A short hand-curated rules sheet (block density per act, elite buff awareness, boss-prep checklist) provided as a system prompt addendum might close roughly half of combat-misplay deaths. This is the B0-with-priors condition we're testing in trial-v1.
-
Multi-floor planning. Even a 5-floor lookahead on map routing would help. "I'm at 30 HP, there's a rest site in 2 floors, and an elite in 3 — I should path to the rest site first." Humans do this instinctively. Models mostly don't.
-
Combat pattern recognition. Models don't develop "combat templates" — reusable strategies for common encounter types. A human learns "Knowledge Demon is a 4–5 turn race, build for damage and tank Disintegration with orb block." Models re-derive strategy from first principles every combat.
-
Calibrated risk assessment. Best human players know when they're ahead and can take risks (elite fights, risky events) and when they need to play conservatively. Models seem to have a fixed risk tolerance regardless of game state.
-
Better state exposure (this one's on us, not the models). Run25's death was an epistemic failure caused by an incomplete bridge schema. Adding
combat.pendingEndOfTurnto the state JSON is the single highest-ROI improvement we can make for v0.2.x.
Limitations of trial-v0
- k=1 per cell. Each model–character pair was run exactly once. The observed spread is large (run10 vs run11, same model: 30+ floor difference). Trial-v1 runs k=3 per cell.
- Single knowledge condition. All runs are zero-shot. Trial-v1 adds a B0-with-priors arm with a curated rules sheet.
- Ascension 0 only. Higher ascensions introduce additional constraints that would magnify the observed failure modes. Defer until we see non-zero win rates at A0.
- No prompt optimization. The agent prompt is frozen for the trial. Prompt engineering could improve results substantially; that's a separate, valid axis to test, but not this one.
- One bridge implementation. Bugs in HermesBridge contributed to 3 of 22 non-victorious halts (the IPC-desync stalls in runs 08, 15, 17). v0.2.0 closes most of the catalogued issues. Run25's epistemic-failure death was caused by a state-schema gap, not a bridge bug per se, but it's a bridge improvement to be made.
- No baseline. We don't know what a competent human player scores zero-shot on the same characters at A0. Anecdotally: a competent player wins ~30–50% of A0 runs. We have no rigorous comparison.
What's next: trial-v1
- Two arms: A0-zero-shot (control) and B0-with-priors (intervention). B0 ships a hand-curated rules sheet as a system prompt addendum, testing whether the failure modes are knowledge gaps or reasoning gaps.
- k=3 per cell: 5 models × 5 characters × 2 conditions × 3 runs = 150 runs.
- Composite score:
floors + 10·act + 50·victory − 0.1·errors. Frozen post-trial-v0 to avoid cherry-picking. - HermesBridge ≥ v0.2.0: state-version field, ForceRefresh verb, state_inconsistent halt-event, boss-identity exposure. Pre-flight DLL check enforced at run start.
- Schema additions (planned for v0.2.x mid-trial):
combat.pendingEndOfTurnto expose Frost-orb passives, EoT damage, status decay — the data the run25 agent needed and didn't have. - Python port:
tools/spire_bridge.pyreplacing the PowerShell glue for cross-platform contributor reach. The bridge mod itself stays in C# (it's pinned to the game runtime); only the operator-side tooling moves.
Reproducibility
SpireBench is fully open-source and designed to be reproducible.
What you need:
- Slay the Spire 2 on Steam (Early Access, ~$30).
- HermesBridge mod (free, GitHub).
- An LLM API key (any provider).
- OpenCode or any agent framework that can read files and execute commands.
To run your own benchmark:
- Install HermesBridge per the README.
- Configure your agent with the protocol and agent prompt.
- Run. Record. Submit.
Full data:
- runs.csv — all trial-v0 runs with 50+ fields per row.
- Per-run records with decision logs, bridge findings, and agent commentary.
- Raw
.runsave files from the game itself (ground truth). - Findings audit — the full bridge-bug + agent-pattern + cost analysis underlying this writeup.
Appendix
A. Per-character results
| Character | Runs | Victories | Median Floor | Max Floor |
|---|---|---|---|---|
| Ironclad | 5 | 0 | 20 | 50 |
| Silent | 5 | 0 | 17 | 28 |
| Defect | 5 | 0 | 22 | 41 |
| Regent | 5 | 0 | 17 | 19 |
| Necrobinder | 5 | 0 | 17 | 23 |
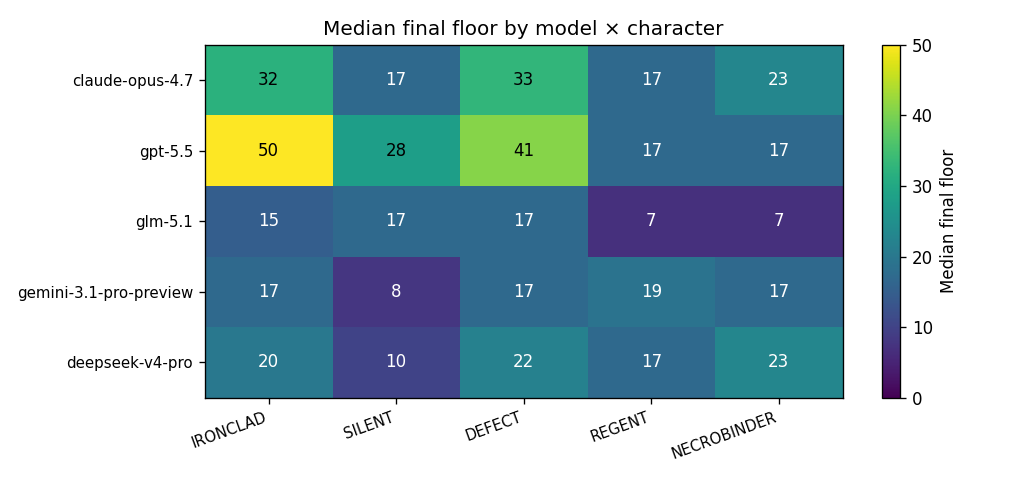
Ironclad is "easiest" in the sense that the highest run was an Ironclad run, but the median is 20 because GPT-5.5 carries the average. Defect shows the biggest spread — agents either build a working orb engine or die in Act 1.
B. Death log (full)
| Run | Model | Character | Floor | Cause / Killer |
|---|---|---|---|---|
| run01 | GLM-5.1 | Ironclad | 15 | map_routing |
| run02 | GLM-5.1 | Silent | 17 | combat_misplay (The Kin boss) |
| run03 | GLM-5.1 | Regent | 7 | normal-monster routing |
| run04 | GLM-5.1 | Necrobinder | 7 | deck_bloat (no win condition) |
| run05 | GLM-5.1 | Defect | 17 | Act 1 boss under-prepped |
| run06 | Gemini 3.1 Pro | Ironclad | 17 | Act 1 boss |
| run07 | Gemini 3.1 Pro | Silent | 8 | potion_misclick |
| run08 | Gemini 3.1 Pro | Regent | 19 | stall (IsTravelEnabled desync, abandoned) |
| run09 | Gemini 3.1 Pro | Necrobinder | 17 | Act 1 boss |
| run10 | Gemini 3.1 Pro | Defect | 17 | Act 1 boss |
| run11 | GPT-5.5 | Ironclad | 50 | Test Subject #C14 (Act 3 boss) |
| run12 | GPT-5.5 | Silent | 28 | Act 2 elite |
| run13 | GPT-5.5 | Regent | 17 | Act 1 boss |
| run14 | GPT-5.5 | Necrobinder | 17 | Act 1 boss |
| run15 | GPT-5.5 | Defect | 41 | stall (post-treasure 0-available, Act 3) |
| run16 | DeepSeek V4 Pro | Ironclad | 20 | Act 2 normal monster |
| run17 | DeepSeek V4 Pro | Silent | 10 | stall (post-treasure 0-available) |
| run18 | DeepSeek V4 Pro | Regent | 17 | Act 1 boss |
| run19 | DeepSeek V4 Pro | Necrobinder | 23 | Act 2 normal monster (combat_misplay) |
| run20 | DeepSeek V4 Pro | Defect | 22 | Act 2 normal monster (combat_misplay) |
| run21 | Claude Opus 4.7 | Ironclad | 32 | Hunter Killer elite (Act 2) |
| run22 | Claude Opus 4.7 | Silent | 17 | The Kin (Act 1 boss) |
| run23 | Claude Opus 4.7 | Regent | 17 | Vantom (Act 1 boss; lethal_line_arithmetic, –5HP) |
| run24 | Claude Opus 4.7 | Necrobinder | 23 | Spiny Toad (Act 2 normal; thorns_under_respect) |
| run25 | Claude Opus 4.7 | Defect | 33 | Knowledge Demon (Act 2 boss; eot_resolution_miscalc) |
C. Example combat: the Knowledge Demon T3
The agent's own decision log for run25's lethal turn, lightly edited for clarity:
T3 plan: Hotfix (echoed via Echo Form, +4 Focus) → Focused Strike (+1 Focus, 9 dmg, FS 9 dmg landed) → Sunder (24 dmg) → Strength Potion (+2 Str) → Metamorphosis (seed +3 free attacks). Pre-EOT projected: 14 Frost-passive block + 5 self-dmg from Disintegration. Survival at HP 2 after KD's 24-dmg attack.
The play actually executed correctly. The miscalculation was on the
state-read between Sunder and EndTurn: the bridge reported Block: 0
on the player line, and the agent treated that as "0 block coming into
EOT" rather than "0 block right now, EOT passives pending." When EOT
resolved, the Frost orbs granted block in a different order than the
agent had projected — one passive trigger short of survival.
The agent identified the cause in its post-mortem:
Block calculation likely off by one Frost orb passive trigger or Disintegration tick ordering vs. block grant.
This is exactly right. The bridge schema didn't expose the EOT resolution order. We're adding it.